Why our first customer at Salv was fake

 Once upon the summer of 2019, we had a problem. And no, it wasn’t just that our name was still the far nerdier “Dataminer” — thankfully, we quickly fixed that.
Once upon the summer of 2019, we had a problem. And no, it wasn’t just that our name was still the far nerdier “Dataminer” — thankfully, we quickly fixed that.
You see, at Salv we had just pivoted from a fraud platform to an AML (anti-money laundering) platform, but we had the same problem every new startup had. We didn’t have customers. And, well, to find customers we needed to show them our product. And to show them our product, we needed data. And where the heck were we going to find data just lying around?
That’s when, as data scientists, we had a dream. A dream to have a large enough, diverse enough, complex enough, and fresh enough dataset that we could demo our product to potential customers and, ultimately, find the kinds of criminal networks that would enable us to test our software and try out real-life transaction monitoring scenarios.
And, well, to do that, we needed data somehow.

How did you get data?
To get data to show prospective customers, we had a few options:
- Use real bank data. While this would have been a dream, in real life, it’s never an option. Sad for us data nerds.
- Use the prospective customer’s data in hashed format. That would require a bunch of work on behalf of the customer upfront just to see our product, and we didn’t think they’d be likely to agree. Plus, if it was a small fintech that hadn’t launched, they wouldn’t even have data to offer. And, regardless, hashing is hard work.
- Use real-life non-bank data and make it into bank transactions. This could be possible. For example, I found a huge set of real life New York taxi data with persons, transaction amounts, start times, end times, etc. That could work. We could use that data as the base and then build bank-type transaction information on top. While not a bad idea, the problem came in when we started thinking about the fact that all the datasets, including taxi data, were finite. If we wanted to scale the data from 10,000 rows to 3,000,000 rows, it would be tough. Sure, we could do a little swapping and duplicating magic, but it wouldn’t be the same.
- Create bank-like data ourselves. As our team of data scientists talked more and more, we realized there were some basic algorithms we could use to generate life-like bank-like transactions. A base set of naming conventions. Behavioural rules. A population registry that resembled the real world. Once we set it up, it would continue generating life-like bank data on its own. It could scale.
Which option did you pick?
Well, the title probably gave our choice away.
In order to protect the innocent, in R, we created a realistic world of people, businesses, transactions, and crooks — none of which ever existed. Well, except for the occasional sanctioned entity. And that’s how Fakebank was born. Full of all kinds of fake transactions, people, companies, and crime, Fakebank is exactly what we data scientists at Salv were dreaming of.
Officially, Fakebank is a database of artificially-generated financial transactions. Unofficially, if I do say so myself, it’s far more interesting.
Last summer, when we launched Fakebank, it had 0 customers. As I write today, Fakebank now has 102,000 — and growing. But we’ve built is so that we can expand to even something like 3 million in a matter of days. We just haven’t seen the need. Yet.
If you’re a data geek like me, then get excited, because I’m going to tell you all the nitty gritty details of how we created it. If you’re not a data geek, well, I think you still may find the process interesting. Or, at the very least, you can impress your math nerd friends the next time you have lunch.

What services does Fakebank offer?
To be frank, Fakebank isn’t exactly a high street bank — its offerings are a bit sparse. At the moment, Fakebank has the following financial services implemented:
- international wire transfer
- national wire transfer (with a given list of banks)
- internal wire transfer (within Fakebank)
- cash withdrawal (using credit/debit card via ATM)
- cash deposit (using credit/debit card via ATM)
But, if you’re a prospective client worried that Fakebank is too simple, we can easily add a laundry list of Fakebank services like debit card payments and loans if needed. At least, we can add services way easier than you can launch them in real life. No offense.

Who uses Fakebank?
As you might have suspected, Fakebank operates in Fakenation as a part of Fakeworld. As an official member state, Fakenation has an individual population registry and a business registry. And it is to this set of fake people and fake businesses in its fake nation that Fakebank markets its financial products and services.
The good news is that Fakebank has some pretty good marketing. Which is why, once an hour, a bunch of people and businesses from those population and business registries are so impressed by Fakebank’s adverts that they become Fakebank customers.
Voila! Converted customers. Wish it was that easy in real life, eh?
Fakenation’s individual and business registries
If we pull back the curtains for a second, you’ll see that when we started this project, we combined our data science nerd power, a lot of googling, and our nearest friends in the financial industry. Which is how we came up with a base list of 44 individuals and 23 business types.
Fun fact, if you look through the names and addresses, you’ll see they often have an Estonian flavour. Or have a very not Estonian name but happen to live in Estonia in a town that doesn’t actually exist. Go figure for a team of 5 Estonian data scientists.
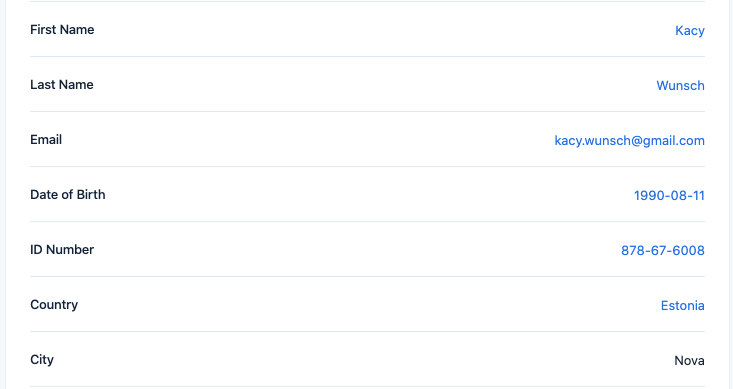 Apparently “Kacy Wunsch”, definitely not an Estonian name, happily lives in Estonia.
Apparently “Kacy Wunsch”, definitely not an Estonian name, happily lives in Estonia.
From there, we added a really long list of various characteristics, and then options for each characteristic. Top it off with a random name generator and, boom, you have the basis of Fakenation’s individual and business registries.
As mentioned before, it’s from these registries that Fakebank “converts” entities into customers.
The reason we decided to start our dataset with a with registries as our base is many-fold:
- We can set up complex shareholder networks for businesses.
- We can use the registries to populate data for multiple banks.
- We can generate a network of transactions between banks.
- We can create user networks between banks, because banks X and Y can also be set up to convert entities from the same register.
Fakebank’s customer profiles
Just like in real life, each person and business from those Fakenation registries are unique. Thus, each Fakebank customer has their own set of unique data that makes up that person or business. For example — Sly Therin, private person, 30-39 years old, employee, averages 40 transactions per month, minimum outgoing 1€, maximum outgoing 3000€, min incoming 1600€, maximum incoming 2000€.
Fakebank customer profiles have data on:
- Average monthly transaction amounts, along with minimum & maximum of a single transaction
- Average monthly transaction count
- Age range of user (individuals)
- Founding year (businesses)
- Shareholder list (businesses)
Fakebank customer bank accounts
Once an individual or business succumbs to the marketing ploys of Fakebank and signs up to become a Fakebank customer, we automatically assign them anywhere from 1 to 5 bank accounts inside Fakebank, along with a corresponding currency tied to each specific account. Just like a real human.
Today, Fakebank converts around 300 new customers per day, but that will increase gradually over time.
Generating the data
As mentioned, impressively, Fakebank manages to convert more customers — individuals and businesses alike — once per hour. And these customers then, obviously, generate their own transactions. Transactions data is set to generate every minute.
Currently as I write, Fakebank has around 9,000 transactions per hour and 80,000 transactions a day. Not bad growth for a startup bank, eh?

How do you spot suspicious activity and entities?
If all of Fakebank’s customers were completely innocent, then you and I probably wouldn’t care. And, well, that would be pretty boring. Especially if you’re testing an AML platform like our potential customers are.
So, good news! Or, rather, bad news — just like in real life, Fakebank has a bunch of shady characters and transactions happening all the time. At random intervals, shady transactions are generated inside Fakebank. Usually every day a few SAR (suspicious activity report) cases are created.
Defining suspicious activity
To define what was suspicious, inside Salv, a bunch of people sat together and put together a list of set scenarios that would be considered suspicious activity. There’s a long list of these actions, but, for example it might mean quickly emptying an account after a large sum is received. Or a customer who normally transacts in smaller amounts suddenly sends a massive amount. Or even if someone just receives an unusually high amount from someone in a high-risk country.
The more fun part is that we made sure that around 10% of the cases would set off some sort of alert to check, but then, when you dig deeper, you’ll find the activity is quite normal. The real criminals are less than 1%.
Sanctioned counterparties
Sanctions is the one scenario in which Fakebank doesn’t use fake data — we deemed it vital in order to test the efficacy of KYC procedures. That’s why, at random intervals, Fakebank customers, counterparties and business shareholders are drawn from the Dow Jones’ Sanctioned Persons database to check against.
Counterparties
As mentioned, Fakebank is a part of Fakenation. And Fakebank customers all come from Fakenation’s individual and business registries.
However, the same isn’t necessarily true of customer counterparties. If the Fakebank customer is involved with a counterparty from outside of the Fakenation registry, then it is generated from a separate registry of Fake-ForeignNation Counterparties. And, as you might imagine, different fake foreign nations also hold different levels of risk. Smart, right?
Currently, around 90% of Fakebank transactions are generated by using connections with entities listed in the Fakenation’s individuals’ register. About 9% are generated randomly with a random counterparty selected from the counterparty database.
About 1% of transactions have completely random counterparty (generated at the moment of transaction).
Built-in complexities and networks
Life is complex — even in Fakeworld. Which is why, in order to mimic real life situations, we built some complexities into the data:
- Built-in connections. Generated Fakeworld data has randomly generated, built-in connections between users. Like employer-employee relationships for salary payments, regular individuals paying their monthly utility bills, friends who split a pub bill, and even family members — but without the drama, and, sadly, without the same last names. Which is an important note. These connections are still basic. You and your sister won’t have the same last name. And your references won’t indicate the nature of your connection with the other entity.
- Daily transaction rhythms. In real life and in Fakebank, most transactions are sent on workdays between 8-18. On the weekends and off-business hours the volumes are lower. Smart, right?
- Transaction amount patterns. While the transactions amounts are generated randomly, they do have pre-given parameters taken from that particular user and their connections’ profiles. Mostly exponential distribution is used to generate amounts. Which, in plain English, means that amounts are mostly small, but with occasional higher-end amounts.
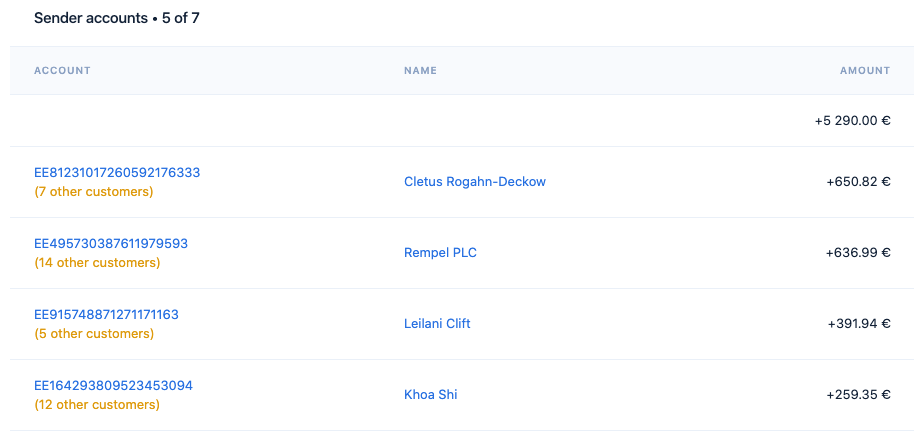 A few small transactions and then… a bit bigger one.
A few small transactions and then… a bit bigger one.
- Customers with multiple accounts. Customers might have a regular account in GBP, a savings account in EUR, and a USD account for investments. Fakebank customers have anywhere from 1-5 accounts, but only one currency per account.
- Randomly assigned SICs. Businesses have a Standard Industrial Classification (SIC) codes randomly assigned to them so you can tell if it’s food service, retail, IT, finance, or whatever else comes up. Although, as a note, this is also a fairly basic function. It won’t correlate to shareholders, transaction amounts, or any other data.
- Everyday references — with an occasional surprise. For around 90% of Fakebank customer transactions, the references are generated based on connection parameters. I.e., an individual person sending money to a business might have a reference like “utility bill.” For the remaining 10%, it gets a little more interesting. The reference will be anywhere from 1 to 3 randomly generated words. Which means you might find yourself chuckling at some of the outcomes — we do.
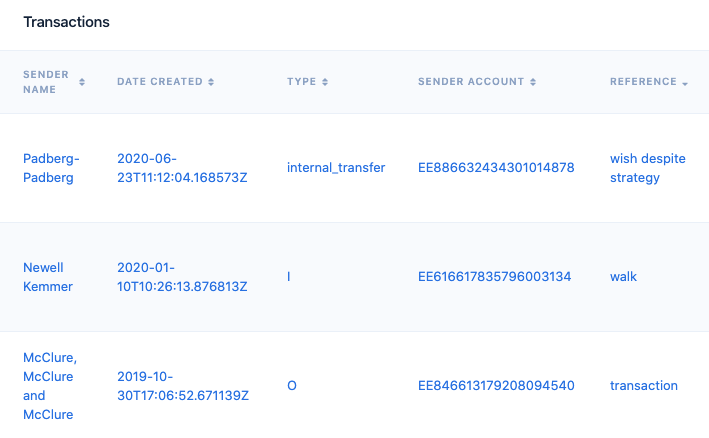 Spot that unusual reference.
Spot that unusual reference.

What’s in a transaction?
Finally, you’ll probably want to know about the actual transactions. We did our best to make them resemble real ones — along with auxiliary tables like account details, account balance, credit card details etc.
But, as we mentioned earlier, Fakebank doesn’t have a complex product offering. So these transactions are modeled off of a commercial bank that offers these types of limited services.
Included transaction information
For every transaction you’ll find in Fakebank, you’ll also find all of this basic information:
- Financial details — currency, amount, exchange rate (taken from live source), and reference text.
- Transaction type — i.e. whether it was a deposit, a withdrawal, or a wire transfer
- Money direction — whether the transaction was incoming or outgoing
- Status — pending, completed, cancelled, or suspended
- Counterparty details — name, account, bank’s SWIFT code

How do you generate individual and business user datasets?
Non-data people, this is a little boring, so you can probably skip to the next section. But if you want the details, here’s the order:
Generating individual user transactions
Salv’s seed data for individuals → Data is then generated into Fakenation’s individuals registry → Becomes a Fakebank customer → Transactions are generated according to customer’s individual profiles or the customer’s connections.
Generating business transactions
Salv’s seed data for businesses → Data is then generated into Fakenation’s business registry (with some UBOs from the individuals registry) → Business then becomes a Fakebank customer → Then transactions are generated according to that business profile
How have you benefited from generating your own data?
When we began building Fakebank our use case was rather narrow, as time went on we realized there were some massive benefits to having our very own fake customer.
- Data for live demos. This, of course, helped enormously. Instead of showing potential customers a set of static screenshots, we could show them our product in action.
- Product improvements. It’s far better to learn on a Fakebank than on a real customer. One time, a bug in our data-generation code brought down the creation of data for an entire week. Once we finally got it back up, it flooded our platform with a massive amount of data — which really tested our limits. That helped us expose some of our platform’s weaknesses and fix them.
- Performance testing. With the previous example, when all the data came in one huge wave, it had the happy side effect of testing our platform’s ability to handle a large load. Afterwards, our product team used the experience to make some much needed improvements. And make sure it was even faster.
- User experience testing. AML agents need a lot of info to make tough decisions — Crook? Or no crook? With Fakebank, we have a massive amount of data on these Fake customers, but it then became quite clear that an investigator would need to see the data in certain arrangements. Having synthetic data really helped our UX designers manage what AML agents saw in a single view, without first failing on real customers. Scenario and rules testing.* Our product team and data scientists constantly want to test new languages and rules to make sure they’re performing as intended. But without data, it’s impossible. Now that they have Fakebank and its band of Fakecustomers, it’s easy.
- Platform monitoring. Without any data flowing to the platform, it’s much harder to monitor the nuances of uptime and downtime. Now, with Fakebank, we can.
- Teaching Salvers more AML. Some of our Salvers don’t have an AML background but really want to learn a lot more. That’s why we organized a hackathon — in a bog, of course — where Salvers learned how to write a scenario in SQL and then find out how many criminals they could catch using their new rules. Each team had a different “shady” scenario and a data scientist as part of their team to help write the rules. Unanimously, Salvers felt great to spending time in the shoes of everyday AML investigators— even for a few hours.
 Several teams of Salvers working on being an AML agent for a day.
Several teams of Salvers working on being an AML agent for a day.
- Testing AML agent skills. An idea we’ve had for a while is to eventually use the platform to help teams check their skills of telling suspicious behaviour from criminal behaviour. We love the idea of giving back to AML teams that are already working so hard, but it’ll probably be awhile before we get to this one. But someday, we hope!

That’s just an overview
All right all right. Fascinating details over.
But, believe it or not, this really is just a quick overview. If you’re interested in how you can try out Fakebank, learning more about how it works, or think you might want to use the dataset, then get in touch directly with me: [email protected]
This is what gets me up in the morning.





