Feature development at Salv: data upload case study

When it comes to feature development, we try to involve engineers as early as possible. Why? In our experience, involving an engineer early on leads to better analysis, better design, and better scoping of features. Normally, a feature is planned in cooperation between an engineer (the feature lead), product manager, designer, and whoever else they decide to involve. The engineer joins at the very beginning and leads the process through a pre-work phase.
Let me explain how this works with the following case study.
Data upload case study
Problem: data upload failure
The project that inspired this case study was triggered by a very common problem reported by our customers who could not seamlessly upload data to Salv’s AML Platform. As long as the data was correct, it worked just fine. However, the data containing errors didn’t immediately make it to the platform. Figuring out the error resulted in the added headaches of searching through endless application logs. We wanted to break free. But the jail break didn’t happen overnight.
At some point, we realised that the flywheel of AML Platform was turning at a lower speed, making it difficult to integrate new customers. Integration was taking longer, it was harder to deliver value to our customers, it was affecting the sales, too.
Solution: new user path and system behaviour
We identified our main challenge – data upload failure. Before we could come up with a solution, we had to collect all possible information, discuss it during the project kick-off meeting, and decide on the next steps.
It’s important to point out that we were not trying to build a brand new feature – we wanted to improve what we already had. Normally, we would collect customers’ feedback through user reviews, side-by-sides, or surveys. However, this time, for the reasons explained above, we gathered the necessary insights in-house.
At the project kick-off meeting we listed all the issues leading data upload failure:
- Transaction upload was possible only after the senders or recipients were already in the system
- Data upload statuses were difficult to understand, naming didn’t make sense
- There was no auto refresh after upload was completed
- Wait time was not designed, failure description messages were confusing
- Users made mistakes with timestamp fields and separators when putting together a CSV file for upload
By improving our data upload, we were hoping to speed up customer onboarding and integration, and take some pressure off our integration team. At the next kick-off meeting, we identified the two main issues resulting in data upload failure:
- Mistakes in CSV files before the upload: we agreed that the new solution should include a preview component in the browser, support a wider separator selection, and an easier way to report errors in CSV files.
- Confusing failure description messages: it was clear to all of us that we needed better error messages.
Based on the agreed goals and expectations, we mapped out a desired user path and system behaviour throughout the data upload process, making sure this could be achieved with a reasonable engineering effort.
This blog post follows a series that concentrates on product engineering at Salv. Previously we have shared Salv’s engineering key principles.
Data upload: new design
The new design was built around the same logic: using drag and drop to move the files around. Once this is done, you can see a modal window and select the type of data for upload, pick the matching separator, and use a visual preview to make sure that everything is in order. The users can view the data upload progress in the Upload History table, which also has a few design improvements. Namely, the status of the file is communicated more clearly, and it is also possible to track the progress in a detailed view.
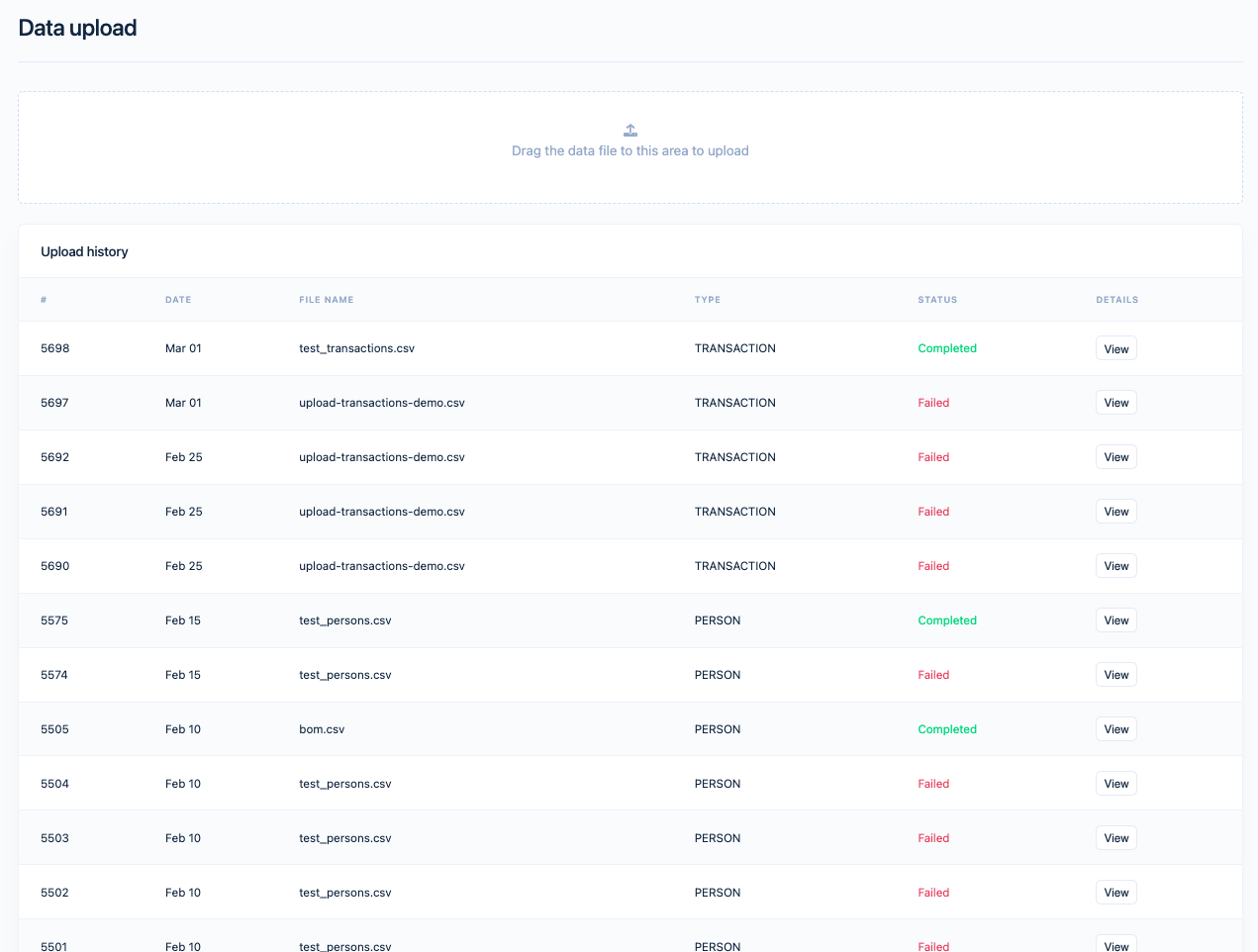
To warn our users against uploading obviously erroneous files, we decided to use built-in automatic validation. Since most of the user mistakes were related to a wrong data format, rather than individual typos, it meant that the whole column of data would contain errors. Therefore, there was no point in validating the whole file right away – the first 10 rows were enough.
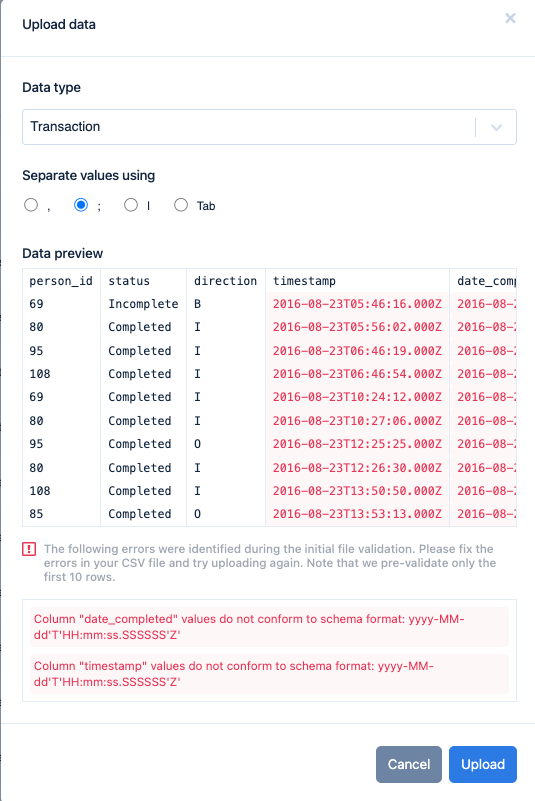
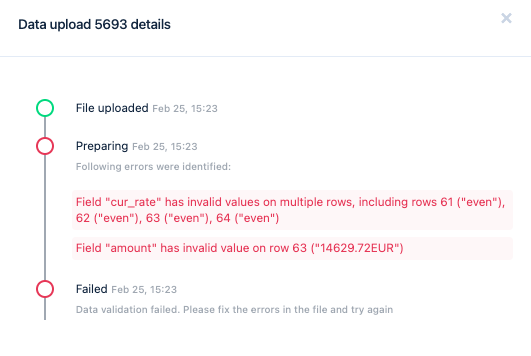
This realisation helped us to keep the initial validation very light-weight, while still catching most of the errors. The errors that occur later in the file are checked in later stages, while the file is still being processed.
Data upload: prototyping
We knew what we were going to build, but the technical implementation was a bit unclear. Specifically, we wanted to know:
- How will in-browser validation work? Will it be difficult to implement?
- Will there be any surprises in the existing code base for validating and processing data upload?
To gain a better understanding of the effort and challenges in solving data upload failure, I started developing new functionality, one slice at a time. The idea was to identify possible blockers early on, so we could redesign the solution with less sweat and tears. Another benefit of this approach was that once the first slice had been delivered, it would allow us to incrementally add new functionality.
Since most of the issues with data upload were caused by a wrong date format, at the start of my prototype project, I focused on date fields in data upload. The planned scope of the prototype project included the following improvements:
- User can see the preview of the first 10 rows of the upload
- All date fields of the first 10 rows of the upload are validated in the browser
- All date fields of the whole file are validated on the server side
The first part of the prototype project went smoothly: showing a preview of a CSV file in the browser was easy. However, when trying to implement validation of the first 10 rows of the upload, I learned something new. Want to know what it was? The date format patterns (e.g. yyyy-mm-dd) were not standardised. 🤔
Our validation on the server side is done using Java DateTimeFormatter, and its date format patterns are shown below:

In the frontend, we were using moment.js, which had implemented date format patterns as shown below:
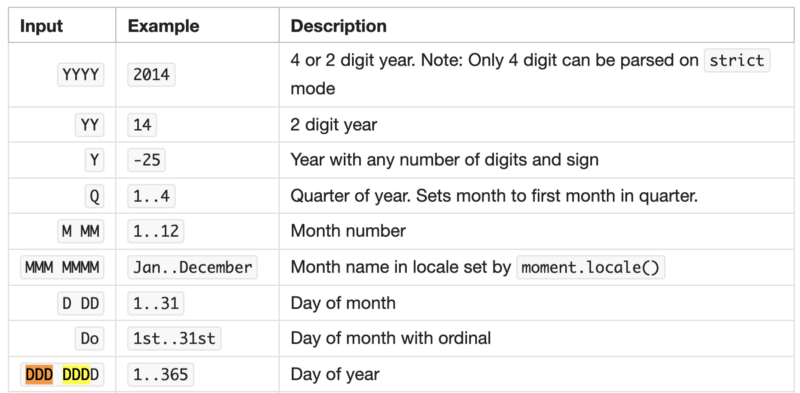
Different date format patterns used by different libraries meant that validating date fields on the client side was not as easy as I had hoped it to be. This also meant that it had been a poor product design decision to require customers to define date format patterns.
At this point we had learned that:
- Displaying a preview of data upload in the browser works well
- Validation of CSV file contents in the browser is possible
- Validating date value against user-defined format pattern is not easy
- To improve user experience, we should allow users to define the date field without having to specify the date format
These learnings were significant to the prototype project’s implementation and success. It was time to discuss if and how we should change our plans and approach to it.
Raido enjoys solving tough problems and holds product reliability dear to his heart. Do you want to know how he does that?
Data upload: implementation
Whereas the engineering pre-work was done mostly by myself, Artjom joined me in the implementation phase. In the end, we split the workload so that I implemented server-side changes, while Artjom took over the client side of things. Everyone focused on his tasks, as a result, we were able to release new functionality in small increments, which took us at least 10 increments.
Even before we were halfway done with data upload fixes, we could see the results of our work: better, faster data uploads, and happier customers. More importantly, through our customers, we learned something that helped us to understand what could be done better. We implemented our findings right away.
Data upload: wrapping up
Data upload was one of the feature development initiatives that helped us to speed up customer onboarding time, which was one of our agreed KPIs. However, this metric alone was not enough for us to understand the full impact of our work. So we asked our data team to create a dashboard with the data upload success rate.
What did we find out? At one point, we had gone from >30% data upload failure rate to <10% failure rate. The number of customers reporting data upload failure significantly decreased. We knew that we had done enough. It was time to wrap up the project and move on to solve other problems.
Data upload: project retro
At Salv, we love learning from our successes as well as our failures. Did someone screw up? Not a problem, we respond with a blameless post-mortem. Apart from that, we run team retros, OKR retros, and project retros.
At the end of the project, we exchanged important learnings during the data upload retro. What did we learn from it?
- Full context: when a new person joins the project, we need to give them the full context, and explain the customer impact.
- Project stand-ups: project stand-ups add a lot of value when multiple engineers are involved. Note: we do regular project stand-ups, and they have done wonders to improve our collaboration and motivation.
Acknowledgements
The core team that wiped data upload failure from Salv’s AML Platform consisted of Artjom and myself as engineers, Tõnis as product lead, Taavet as designer. Many other people contributed as well.
Artjom, Tõnis and Taavet helped me to finish this article, and added valuable comments and suggestions. Taavet wrote the section about design.
This is just one of many projects
By now, you must have a better understanding of our feature development process. You must also have a pretty good idea of what it means to be a product engineer at Salv.
We hire smart engineers and give them freedom to thrive. If you like how we work and would like to join us on our mission to beat financial crime, check out our Careers page. Don’t be afraid to tell us if you want to find out more. 🙃





